Size Matters; It may be the only thing that matters
OK I’ll start with a disclaimer; I’m going to exaggerate some. But actually probably less than you might think if you haven’t been down this road before.
A ton of time is spent teaching prospective engineers about algorithmic complexity. They learn stuff like “sort is O(n*log(n))” and so forth. This is sort of useful, but it’s important to remember that this usually isn’t the most important thing when thinking about how to build systems; actually I’d go so far as to say it’s rarely the most important thing.
What is the most important thing? That’s easy, it’s almost always data density and data locality.
Why?
Because in the time it takes to field one top level cache miss you could probably have retired something like 150 instructions. And do not even get me started on page faults and other VM overheads.
Because of this, it is almost always the case that you can better model your program’s overall cost by totally disregarding all the direct instruction costs and considering only the memory factors. Count cache misses not instructions, or count page faults not instructions.
You see, while many sorts are O(n*log(n)) you must remember that this classic analysis is talking about the number of comparisons not instructions and certainly not time. To get a handle on the cost of the sort you need to consider the nature of the comparisons and the memory structure. The representation of the items to be sorted will make a huge difference. When considering the cost of sorting a bunch of strings — WHERE the strings are in memory and how they are represented will make a huge difference. Good encodings could easily save you half the memory and thereby mightily reduce the cache misses… or page faults. Easily paying for the extra comparison cost…
I’ve written about representation many times: Like this old article. But the bottom line is always the same: dense encoding, rich in values, and low in pointers are almost certainly the best.
While I used sorting as an example above, it applies generally to most algorithms you will encounter. Now again I’m exaggerating, there are cases where you have to iterate over the very same data a lot and so the memory costs are minimal and it’s all about the path-length, but actually that’s much less common than you might think (despite famous examples). Most code that gets written isn’t very “loopy” and is going to make a single pass over a variety of items. This is typical UI code that walks items to draw, or walks resources to create a view, or otherwise does some kind of transition. A tight representation in these cases will allow you to economically visit the all your data. Or if you like, there’s a whole lot of O(n) code out there and density is almost always king in those cases.
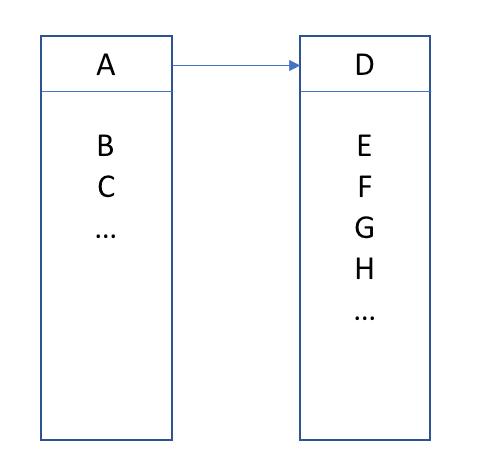
I’ve been teaching performance classes for a long time now; one of the things I like to do as talk about various data structures and how to evaluate them. There isn’t any complete answer but I have a memorable rule-of-thumb. Let’s just consider this picture here:

Now as we can clearly see from the above picture, pointer AB is a nice short pointer, that’s perfectly safe; likewise EF, FG, and GH are harmless pointers that wouldn’t hurt a fly. Whereas AD looks kind of scary and BC is clearly a major hazard. That’s how we read this diagram right?
Well… of course not…
It turns out all the pointers are equally horrible and a pointer rich data structure like the above is not likely to perform very well at all. Now if there really are exactly 8 objects then meh, whatever, but usually this is just a piece of the world, and if you’re reading this I’m sure you’ve seen far worse at the core of an application.
So how do you evaluate a candidate data structure like this for performance? Well it’s pretty easy. Just draw it like the above, then for every arrow you draw, slap your own wrist pretty hard. Then you can tell how good it is by how much your hand hurts.
You’ll soon find yourself vastly preferring diagrams like the below:
Big objects with lots of data and some kind of internal growth strategy.
A friend of mine once said, “Arrays are the most under utilized data structure” and I think he was right.
Now again, what I’m saying is a simplification, but I actually believe it is very much the common case. It’s all about space and density. Cases where algorithmic complexity dominate the costs are actually much more exotic. The things I mention above happen basically all the time.
