Wrathmark: An Interesting Compute Workload (Part 1)
Context
I had some interest in learning about how CLR performance had evolved in recent years and comparing how this evolution had happened on ARM vs. X64.
I wanted to get a look at the raw CPU improvements that had been made via JIT tech and so I needed a benchmark that would take a lot of other things off the table. I also wanted something highly portable, and I wanted a baseline against high quality native code.
As it happened, I had just dusted off my old college Othello program (Wrath) which was written in K&R C. I had just finished modernizing it to look like normal modern C and was in the process of adding comments when it occurred to me that if I ported the thing to C# it would make an interesting benchmark.
Why is it interesting?
Well, it runs on fumes. It was designed to run on a VAX780 in 1987. The whole program now easily fits in cache memory. It’s already well tuned from work I did in that era (though I did fix up a few things). It uses basically nothing but printf for I/O and the entire workload is just processing of in-memory data. In short, it’s a good test of basic operations without being an arbitrary microbenchmark. It actually plays the game, so there is meaningfulness to its calculations. The benchmark result is completely deterministic, it evaluates exactly 1,474,559,545 board every time. The same boards. And it allocates basically nothing except for some fixed size stuff at startup, so there is zero GC overhead. The benchmark in managed code will allocate exactly one timer object dynamically during the run. It’s quite fast so it can do the board evaluation in a few minutes. It’s highly portable so it can run on ARM and X64 with no issues. The core data structures are bytes, so endianness isn’t even an issue. The VAX it originally ran on was big endian… it doesn’t matter a fig.
Test Machines
X64:
- model name: Intel(R) Core i9–10940X
- Cores: 14 (single threaded workload)
- clock 3.312 GHz
- cache size 19712 KB
This system is noisy, it’s my workstation, so I ran the benchmark 3 times and used the best result. That right there should tell you the level of accuracy I’m going for here. See disclaimers later. 5% variation run to run with no changes was not uncommon.
ARM64:
- model name: Neoverse-N1
- Cores: 2 (A lie, it’s virtualized, it’s probably really 16)
- cpu MHz: Not reported by /proc/cpuinfo; I wouldn’t believe it anyway
- cache size: L1d 128kiB, L1i 128kiB, L2 2 MiB, L3 32MiB
This system was quite clean. Repeated results often had 5 digits of agreement.
The ARM64 tests were run on AlmaLinux 9.2. The X64 tests on WSL Ubuntu 22.04.3 LTS.
Special guest appearance by a Macbook with Apple M2 Silicon for selected benchmarks as another ARM64 comparison.
Interpreting These Results
I obviously think these results are interesting or I wouldn’t report them, but readers must remember that this is just one workload. I am looking for just a few specific insights from this workload which is why I picked it (also because it was handy). These results say basically nothing about other workloads.
The Benchmarks
Wrath Native
This is the (nearly) original C code compiled with the Clang I could get most easily on the system in question (14 or 15).
Wrath Sharp with Vector128 Storage
This is a direct port to C# that stores the boards in a single Vector128. The program uses bitboards — 8 bytes can hold the bits for black, and another 8 for white. A single Vector128 can hold both. This seemed like a great way to get something like inline arrays on all versions of .NET that supported Vector128. As we will see, using Vector128 for just storage (no actual SIMD) turns out to be a bad idea.
Wrath Sharp with Standard Arrays
This version has almost exactly the same code but the backing store for the boards becomes a bunch of pre-allocated byte arrays. These are just normal byte[] things. Not that many either because the deepest the recursion can possibly go is about 20. The game allows it to be 32 but that would require waiting a few weeks or so for an evaluation. Pre-allocating 32 boards is plenty. There are similar reasonable bounds on arrays of valid moves and so forth.
Wrath Sharp with Inline Arrays
Again, this version has almost exactly the same code. The array declarations are replaced with the equivalent inline array syntax that is new in .NET 8.0. This allows arrays whose size is fixed at compile time which helps with bounds checking and storage economy.
Source Code and Test Instructions
- https://github.com/ricomariani/wrath-othello
- use the main branch
CC=clang makebench_all.sh
Results
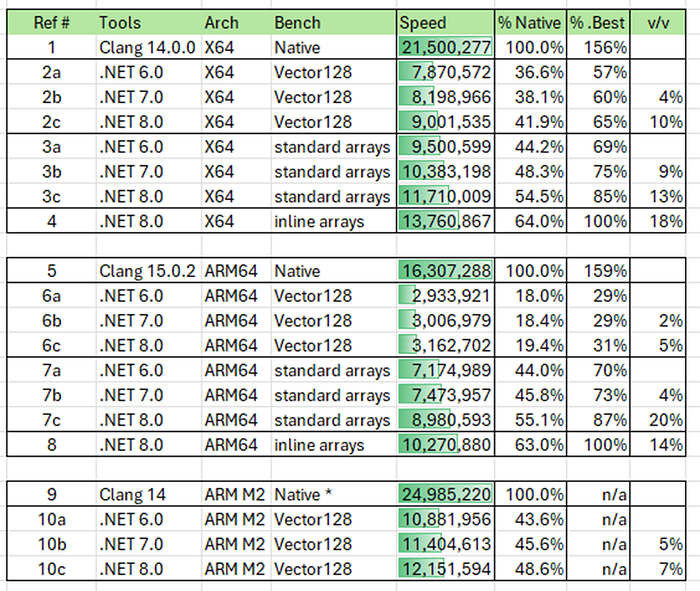
Interpretation
I’ve numbered the results for convenience of discussion, and I’ll have a few comments about each section.
Result 1 gives us an idea how fast the X64 machine we happen to be running on is and it is the benchmark for the other runs. At 21.5 million boards/sec (henceforth b/s) we’re doing a board evaluation every 46.5 nanoseconds. This is not slow. The compiler version makes a difference as I saw gcc runs were frequently slower by as much as 2M b/s (~10%). Every inlining and unrolling choice matters.
Results 2a, 2b, 2c show how Vector128 in C# stacks up against native. The answer is: not too good. As I mentioned “extract a byte from a Vector” is not especially economical. Still 2a, 2b, and 2c show excellent wins version of version in the CLR illustrating that its code quality was going up. The v/v column shows a 4% lift in .NET 7 and then another 10% lift in .NET 8.
I tried the inline arrays version next (result 8) but let’s save the best for last.
Results 3a, 3b, 3c show what happens if you replace the vectors with normal arrays. This gives you the benefit of call by reference semantics and fast access to any given byte. The cost is less locality and more bounds checks. In the vector code the size of the vector is always known at compile time but with standard arrays the data type is byte[] which could be any length. More on that later.
Even so, result 3a handily beats even result 2c. And .NET 8, see result 3c, achieves 54.5% the raw native speed. The v/v column shows a 9% gain going to .NET 7 and a 13% gain going to .NET 8. These are HUGE numbers. In the world of compiler performance developers are doing cartwheels for even a 2% win. Double digit gains (13%!!) are amazing and reflect the awesome power of the new JIT dynamic code-gen.
Saving the best for last, result 4 showcases the new inline array feature. Inline arrays were used for the boards, plus all the lookup tables. As we will see, this materially reduces branches in the generated code. At 13.7M b/s inline arrays gave us an 18% lift (see v/v) and brought us to 64% of full native speed. Keeping in mind this is a raw compute benchmark that is running hot in the cache, the usual places where managed code can give you raw benefits — like fast allocation — are basically non-existent here. And there are no I/O or other blocking operations. This is an acid test for the JIT (on purpose).
Having reached the end of the results, I can now explain the %.Best column. This compares the run speed against the best that .NET can do (.NET with inline arrays). It’s similar math to % native, showing instead the percentage of full managed speed the benchmark attains. Now we can easily see that result 2a was 57% of the best managed code can do.
That’s a wrap for Intel, we can do this again now for ARM64.
Result 5 shows us that our ARM test machine is not too shabby. At ~16.3M b/s it’s right about 75% the speed of the X64 system. Pretty zippy. It only has 2 (virtual) cores, but this is a single threaded workload, so cores won’t matter. Since the ARM system has no other workload, the results were quite stable, often consistent to five significant digits. So here I just used my last run and called it good.
Result 6a, 6b, and 6c show that Vector128 is a hot mess on this particular ARM system. Even mighty .NET 8 only achieves 19.4% of the max native speed. But here is a place where we must remember that ARM architecture has lots of options — by design. If we skip down a bit to the M2 results. We see that in Result 9 the M2 silicon got about 25M b/s but the Vector128 version ran at about 10.8M b/s on .NET 6 and up to 12.1M b/s on .NET 8.
The M2 results tell us that the Vector128 code-gen is not the issue (note: both systems report hardware support for Vector128) but the silicon varies, and this particular silicon has not invested in instructions that help you to “use a vector like an array”. Which makes a lot of sense because using SIMD registers to not do SIMD is kind of weird. ARM is flexible like that.
Result 7a, 7b, 7c run the standard arrays code on ARM and now we are back to normalcy. The array patterns are very normal and the ARM64 CPU is doing an excellent job. Result 7c shows that the ARM64 code is getting a (slightly) higher percentage of the full native performance than X64! The v/v column tells a tale of investment as .NET 8 posts a whopping 20% gain over .NET 7 on this benchmark. HUGE gains in raw array access.
Finally Result 8 is the inline array version on ARM. Here we see another 14% lift compared to normal arrays, reaching 63% the speed of native. Very close to X64. Going from regular arrays on .NET 6 to inline arrays on .NET 8 was a 43% increase in b/s. It seems that .NET 8 has removed any raw ARM penalty associated with code-gen quality.
Unfortunately, I didn’t have access to my own Mac to run more benchmarks there. And I know that the Native benchmark changed a little since those results. But the M2 results were only there to illustrate that there is no general ARM problem with Vector instruction code-gen anyway. Trivia: the M2 results are the fastest I’ve ever seen — at ~40ns per board.
Microarchitectural Analysis
I did a quick study of key CPU counters for selected benchmarks with results in the following sections.
I could not use the runs computed boards/sec because of the likelihood of time interference while harvesting fine-grained CPU counters. I did this analysis only for X64, but hopefully that is still interesting. Getting suitable access to an ARM64 machine that with the counters exposed shouldn’t be so very hard but my VM was not up to the job.
I used duration rather than boards/sec in this table so that all the metrics would be “lower is better.”
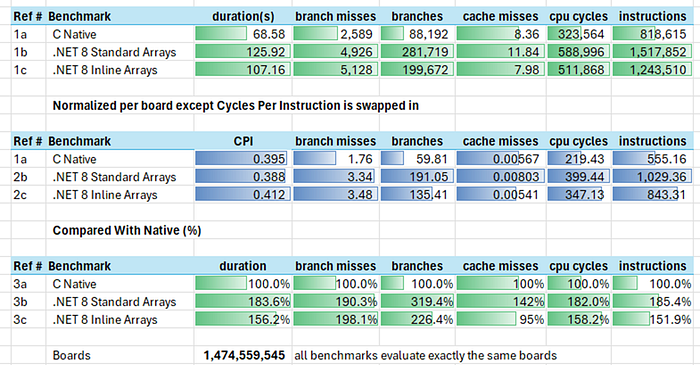
Microarchitectural Results Shape
The first section is the raw results, using duration rather than boards/sec from the previous section. The raw metrics are in millions, except for duration which is in seconds.
The second section is the raw results normalized per board (divide by 1,474,559,545). These metrics are not in millions but rather units/board. The first result changes to CPI (cycles per instruction) because seconds/board doesn’t tell us anything new compared to boards/sec which we’ve discussed at length.
The last section normalizes again, this time as a percentage of the native result. These results are unitless.
Observations
In this workload cache misses are very low, as expected. Looking at rows 1a, 1b, and 1c we see numbers like ~8.4M misses (1a). This may seem like a lot, but on a per board basis (2a) it’s about 6 misses every 1000 boards — that’s more likely to be related to the operating system rescheduling the cores than the actual game algorithm.
There is evidence that locality is worse in the “standard arrays” version with row 3b showing 1.42x the cache misses of native. This is still probably not hurting the speed much.
CPI is excellent with every run near 0.4 cycles/instruction. This is a CPI to dream of.
The managed solutions are much branchier, with the standard arrays coming in at almost 3.2x as many branches (see rows 3b and 3c)
Branch misprediction as a percentage (again rows 3b, 3c) is not worse in managed code, so we’re still doing ok on the prediction cache — it’s the total number of branches that’s the big issue.
The inline array version seems to get the bulk of its increased speed from fewer branches. No big surprise there (row 3c).
With CPI nearly fixed it should also be no surprise that the duration increase is attributable to path length (total number of instructions retired).
My first instinct here was to attribute the extra branches to bounds checks, however, investigation on that front led me to a different conclusion. See below.
Preliminary Conclusions
“Vector128 as an array” is probably just a bad idea until/unless some new ABI that is “passing vectors in registers” friendly happens, which will be hard. Future silicon may choose to invest here but it’s weird, so why would they? M2 did though, so that’s something. With vanilla arrays being better in all cases, I think this is just a cute idea that ends up performing poorly.
Further experiments (see Part 2) have shown that in this case the major branch differences can be attributed to two things:
- The JIT does not unroll loops as aggressively as
clang -O3. Note, this kind of aggressive unrolling is usually a terrible idea (clang is very aggressive when given-O3). The JIT could do this sort of thing but only if informed by excellent runtime metrics that provide proof that it would be worth the space expense. - The JIT made poor use of conditional move and conditional select to elide branches in cases that were similar to a
?:operation. This seems very actionable, and indeed more use of this pattern is likely to be helpful universally, not just on this workload.
Data oriented designs like this one can perform very well. Focusing on eliminating the bounds checking is likely to make a significant difference once the system is down to raw computation on arrays of data.
With “Span<T> in all the places” as a key feature of .NET 8, many systems can hope to be on a plan where they hardly allocate anything and get great throughput. Maybe not a CPI of 0.4 like this benchmark but better than CPIs or 3.0 to 5.0 we sometimes saw in the bad old days of .NET 1.1.
ARM64 has no code-gen quality penalty compared to X64 at this point. Any JIT related deficit seems to have been erased. A solid reason to go with .NET 8 if you are targeting ARM64.
Generally, .NET 8 is a HUGE improvement on raw computation loads like this one.
The analysis continues in Part 2.
[Trivia: “Wrath” got its name because it sounds kid of like “Roth” for Rico’s Othello; but I thought it was less lame]
